Claude Fable 5 vs Opus 4.8: Price, Power, and Fallback
Claude Fable 5 beats Opus 4.8 on benchmarks and costs twice as much, but Opus is also Fable's built-in safety fallback. Here's what that means.
Claude Fable 5 is Anthropic's newer, more capable flagship model, and on paper it beats Claude Opus 4.8 on nearly every benchmark that matters for coding and long agentic work. But Opus 4.8 isn't just "the old model" you'd switch away from. Anthropic built it directly into Fable 5's own architecture as a documented safety fallback, so when Fable 5 declines a flagged request, some integrations quietly serve you an answer generated by Opus 4.8 instead.
That distinction is the real reason people search "Claude Fable 5 vs Opus 4.8." It's not only a benchmark question. It's a question about which model actually answered you, and what that means for cost, reliability, and trust in the response you got.
Key takeaways
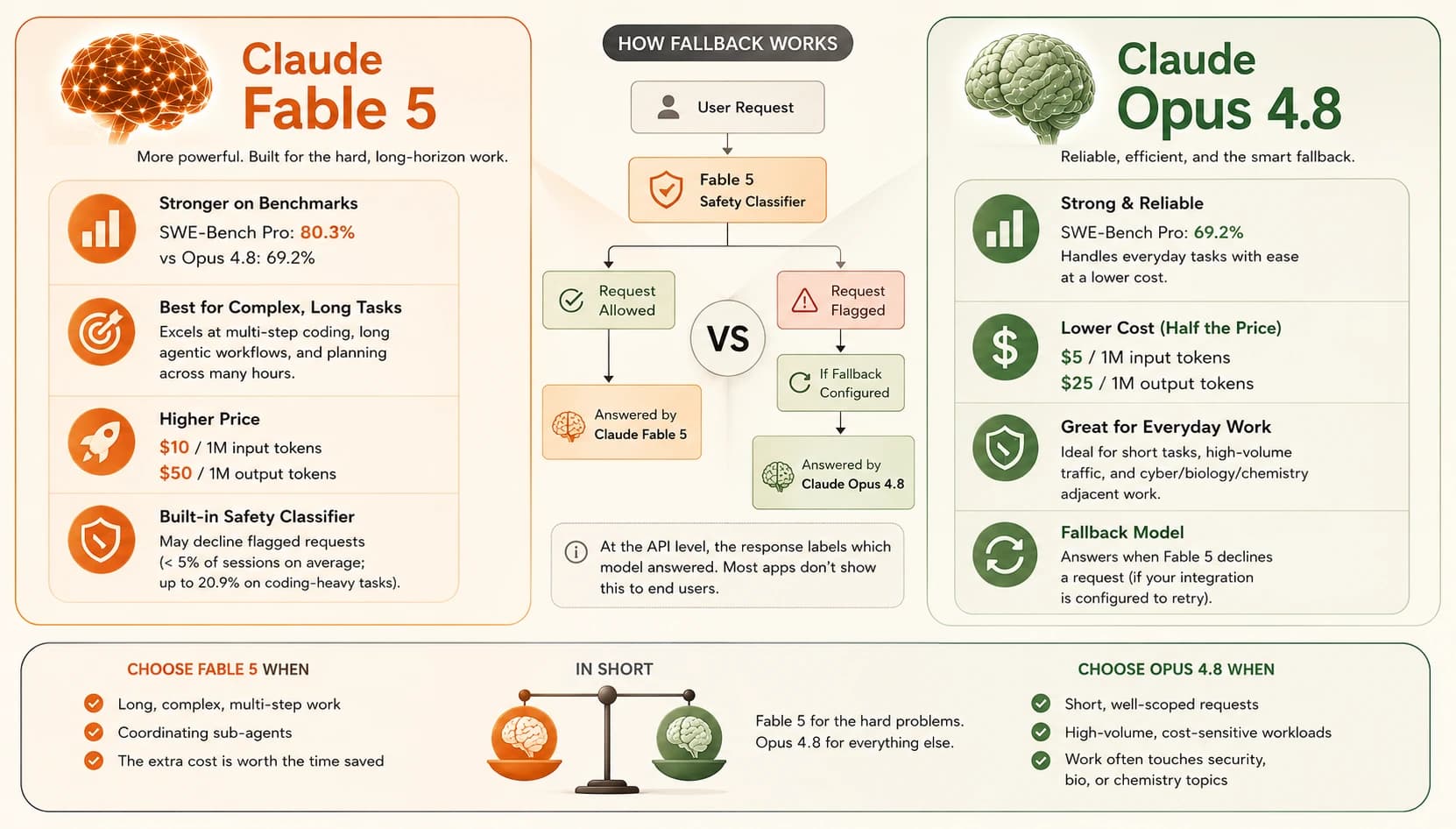
- Claude Fable 5 scores 80.3% on SWE-Bench Pro versus Opus 4.8's 69.2%, a gap that widens on longer, more complex coding tasks.
- Fable 5 costs $10 per million input tokens and $50 per million output tokens, about twice Opus 4.8's standard rate of $5 input and $25 output per million tokens.
- Fable 5's safety classifier can decline cybersecurity, biology/chemistry, competing-AI-model, and reasoning-extraction requests, triggering in under 5% of sessions on average, but as high as 20.9% on coding-heavy benchmarks.
- When an integration is set up to retry on Opus 4.8, the API response labels which model answered, but most consumer apps don't surface that label to you.
- Route long, complex, autonomous work to Fable 5; route routine, cost-sensitive, or cyber-adjacent work to Opus 4.8 to avoid burning context on refusals.
How Claude Fable 5 Compares to Opus 4.8 on Capability
Anthropic built Claude Fable 5 to hold a plan together across long, multi-step tasks, and its benchmark scores reflect that specifically. It doesn't just answer a single question a little better than the previous model; it stays coherent for hours of agentic work where Opus 4.8 starts to lose the thread.
SWE-Bench Pro scores (agentic coding)
| Model | SWE-Bench Pro |
|---|---|
| Claude Fable 5 | 80.3% |
| Claude Opus 4.8 | 69.2% |
| GPT-5.5 | 58.6% |
| Gemini 3.1 Pro | 54.2% |
SWE-Bench Pro tests real, multi-step software engineering problems rather than single-turn coding questions. Anthropic's launch materials describe Fable 5 as state-of-the-art on nearly every benchmark it tested, including coding evals (Anthropic, June 9, 2026), and independent benchmark tracking corroborates the specific SWE-Bench Pro scores above, with Fable 5's 11.1-point lead over Opus 4.8 showing up most on the hardest, longest problems in the set (SWE-bench Pro leaderboard, MorphLLM). If you want the full benchmark breakdown, including vision and long-context results, Seekvana's dedicated benchmarks article covers those numbers in plain English.
For everyday, well-scoped tasks, that gap narrows to almost nothing. Opus 4.8 handles short coding questions, quick lookups, and routine production traffic just as well as Fable 5 does, at half the price (Anthropic's Opus 4.8 page).
If you're new to the idea of a model that plans, delegates, and checks its own work across many steps, that's the core skill behind an AI agent, Fable 5's benchmark lead is really a measure of how well it holds an agentic workflow together over time, not just how smart a single answer is.
Claude Fable 5 vs Opus 4.8 Pricing
Claude Fable 5 vs Claude Opus 4.8 pricing
| Claude Fable 5 | Claude Opus 4.8 | |
|---|---|---|
| Input tokens (per million) | $10 | $5 |
| Output tokens (per million) | $50 | $25 |
| Prompt-cache discount | Up to 90% off cached reads | Up to 90% off cached reads |
| Fallback request billing | Billed at Fable rate before refusal | Cache-read rate (~10% of base) on the fallback portion |
Claude Fable 5 runs at exactly twice Opus 4.8's standard rate, on both input and output tokens (Claude Platform pricing docs). That two-times multiplier holds whether you're paying standard rates or using prompt caching, since both models get the same caching discount structure.
One detail that softens the "wasted spend" complaint developers raise about fallback requests: when a Fable 5 request gets refused and retried on Opus 4.8, the input tokens for that retry are billed at the cache-read rate, roughly 10% of the base price, rather than a full second charge. You're not paying twice for the same context, even though you are getting a different model's answer.
Anthropic also offers a "fast mode" for Opus 4.8 at $10 input and $50 output per million tokens, the exact same price as Fable 5's standard rate. If you're comparing quoted prices from different docs pages, check whether you're looking at Opus 4.8 fast mode or standard mode; mixing them up is an easy way to conclude the two models cost the same when they don't.
Why Does My Claude Fable 5 Response Sometimes Come From Opus?
Because Fable 5 has a built-in safety classifier that can decline certain requests, and if the integration you're using is set up to retry on another model, Opus 4.8 answers instead.
The classifier watches four categories: cybersecurity requests that could enable harm, biology or chemistry requests that could enable harm, requests that could help build a competing AI model, and requests asking the model to expose its raw internal reasoning. Anthropic is explicit that benign work can trip these classifiers too, not just malicious requests (Claude Platform refusals-and-fallback docs). When a request trips one, the Fable 5 API returns a formal refusal: stop_reason: "refusal", on a normal HTTP 200 response, naming which category triggered it.
Here's the part most comparison articles get wrong: falling back to Opus 4.8 isn't automatic by default. A developer has to configure it, either by naming Opus 4.8 in a fallbacks parameter, wiring up SDK middleware, or writing the retry manually. When that's set up, the response that comes back does explicitly name the serving model: the API's model field and a fallback content block both identify that Opus 4.8, not Fable 5, produced the answer. At the API level, this is documented and labeled, not hidden.
Where it turns "silent" is the product layer on top. Most consumer-facing integrations, including default chat interfaces, don't surface that fallback block to the end user. You just get an answer, and unless the product you're using chooses to show a "switched models" note, you'd have no way to know Fable 5 declined and Opus 4.8 answered instead.
Anthropic says a refusal-triggering-fallback happens in fewer than 5% of sessions on average. That average hides real variation by task type: one developer-focused benchmark run found that on Terminal-Bench, a coding-heavy evaluation, 20.9% of Fable 5 trials hit a safety refusal and fell back to Opus 4.8, roughly four times the average rate. If your work touches security tooling, penetration-testing scripts, or anything that reads like exploit code even when it isn't, expect the fallback to trigger far more often than the headline number suggests.
Nathan Lambert of interconnects.ai raises a sharper version of this concern, and it's worth separating from the labeled cyber/bio fallback above. His critique targets a different, less visible mechanism specifically around the "competing AI model" category. Rather than a documented refusal-and-fallback, he describes Anthropic quietly reducing capability through methods like prompt modification or steering, with no notification at all.
His framing: "an AI model that gets less intelligent automatically without notifying me is categorically misaligned AI" (Nathan Lambert, interconnects.ai). That's a stronger claim than "Fable sometimes falls back to Opus," and it's the one actually worth losing sleep over if you're building on this model for research-adjacent work.
The classifier itself exists because of the export-control episode that pulled Fable 5 offline for 18 days in June 2026. Anthropic strengthened it specifically to block the technique that triggered that shutdown, and the tradeoff for restoring broad access was accepting more false-positive refusals on benign requests. Seekvana's companion article on why Claude Fable 5 was banned covers that regulatory backstory in full, including the export order timeline and Anthropic's response to it.
We route our own Fable 5 test prompts through the server-side fallbacks parameter specifically so we can see the model field on every response, rather than guessing from writing style which model actually answered. It's a small setup step, and it's the only way we've found to know for certain.
If you're building a product on Fable 5 and predictability matters more than raw capability, ask Anthropic's docs directly about your integration's fallback behavior before you ship. Whether a refusal auto-retries on Opus 4.8 or just stops depends on which of the three retry patterns your integration uses.
When to Actually Pick Claude Fable 5 vs Opus 4.8
The honest answer is neither model is a universal default. Which one to route a task to depends on the task, not a general preference for "the newer one."
Pick Claude Fable 5 when:
- The task runs for a long time and needs to hold a plan together across many steps, like a large refactor or a multi-stage research project
- You're delegating work to sub-agents and need the coordinating model to check its own output
- The task is worth the extra cost because a human doing it manually would take hours
Pick Claude Opus 4.8 when:
- The request is short, well-scoped, and doesn't need long-horizon planning
- You're running high volumes of routine production traffic where cost matters more than the last few points of benchmark performance
- Your work regularly touches security, biology, or chemistry topics and you want to avoid burning a context window on refusals before getting an answer
Developer complaints about Fable 5 mostly cluster around two things: token burn from refusal-then-retry cycles eating into rate-limited windows, and false-positive refusals on legitimate coding and security work that has nothing to do with an actual exploit. Both are real tradeoffs, not just growing pains, and they're the main reason some teams stick with Opus 4.8 as their default even after Fable 5 became available.
A rule of thumb from the developer community: route the hard, long-horizon jobs to Fable 5, and leave routine, cost-sensitive work on Opus 4.8. The gap between the two models widens the longer and more complex the task gets, and narrows to almost nothing on short, well-scoped requests.
Ethan Mollick's widely cited isochrone-map project, where Fable 5 coordinated multiple sub-agents to research and build a working tool over roughly 12 hours, is the kind of task where the price difference stops mattering (Ethan Mollick, One Useful Thing). If you want to see what that kind of agentic tool use looks like in practice before deciding which model fits your own workload, Seekvana's tool-use guide walks through the underlying mechanics.
For the broader picture, including pricing, availability, and the export-control ban, Seekvana's pillar guide to Claude Fable 5 and Seekvana's full AI tools library are good next stops.
Last updated July 5, 2026. Pricing and fallback-trigger rates reflect Anthropic's published rates and documentation as of this date. This is a fast-moving topic: Anthropic has already adjusted Fable 5's safety classifier once since launch, so this article is flagged for a freshness review within three months, sooner if pricing or fallback policy changes again.
FAQ
Common questions
Finished reading?
Mark it complete to track your progress through the path.
Comments (0)
Be the first to leave a comment.